GPT series and Large Language Models
With the advancement over the past decades, our artificial intelligence has transitioned from Narrow Artificial Intelligent (Narrow AI) to Artificial General Intelligent (AGI).
- Narrow AI: Models are designed and trained for solving a specific task or a limited domain. For example, models that can do face recognition is not able to recognise cat. For different input, you have to design different models: sequences RNN, images/video-CNN, structural-GNN.
- AGI: Transformer can deal with all kind of data, images, texts, structural data, etc by tokenise. The advent of this kind of general architecture can realize different tasks or different modalities.
On the path to fully realising AGI, we are currently in the stage of LLMs, where, despite possessing powerful generative capabilities and outperforming Narrow AI in multi-task scenarios, they are still limited by long-text constraints, have restricted reasoning abilities, lack autonomous decision-making, and struggle with generalisation in unfamiliar tasks.
In this blog, let’s explore the evolution of GPT to gain a deeper understanding of LLMs. We’ll examine how these models have advanced over time, their underlying mechanisms, and their role in shaping the future of AI.
Large Language Models Overview
A Large Language Model (LLM) primarily performs “next-token prediction”, meaning it generates new content based on a given context. The input content can be any form of data that can be tokenized, making LLMs highly versatile. For example, LLMs can be applied to:
- Question Answering: Given a question in text form, generate an appropriate textual answer.
- Machine Translation: Given a sentence in English, generate its corresponding translation in French.
General Training Pipeline of LLMs includes
- Self-supervised Pretraining: In this stage, the model is trained on large-scale, unlabeled data through self-supervised learning. Since there is no direct supervision, the model learns by predicting missing tokens or next tokens within a sentence.
The objective is to learn as much as possible from raw data, enabling the model to acquire
general knowledge and improve its ability to generate coherent data.
However,
at this stage, the model cannot directly meet human expectations. It lacks specific task capabilities, such as following instructions or engaging in meaningful dialogue.
- Supervised Fine Tuning (SFT): Supervised fine-tuning refines the pretrained model to better align with human instructions and task-specific objectives, making it function similarly to a Narrow AI system.
At this stage, the model is trained using
human-labeled datasets, where pairs of input queries and corresponding responses are provided. Common datasets include instruction-following tasks, where the model is trained to respond appropriately when given commands such as “Summarize this article” or “Translate this text”.
However, if the model is trained solely on supervised Q&A data, it may become
too rigid and unable to handle ambiguous or open-ended scenarios effectively. For example, if a model is trained only to produce direct answers, it may fail to respond appropriately in nuanced real-life interactions. Consider the case where a person asks, “What do you think about this issue?”—the response should be more dynamic and context-aware, rather than a fixed answer. Therefore, the model after SFT learns to follow predefined patterns but lacks adaptability to novel instructions. And it can become overly deterministic, failing to provide diverse responses in creative or open-ended contexts.
- Reinforcement Learning from Human Feedback (RLHF): To overcome the limitations of SFT, this stage improves the model’s ability to generate human-preferred responses by incorporating human evaluation and ranking. Instead of training with rigid input-output pairs, RLHF leverages human annotators who rank multiple generated responses based on their quality, coherence, and relevance. The model is then optimized using reinforcement learning, where it learns to prioritize responses that align more closely with human preferences. Unlike SFT, RLHF allows the model to develop greater flexibility and contextual awareness, improving its ability to handle ambiguous, nuanced, and multi-turn conversations.
(More details will be covered later, but let’s first focus on the general idea.)
Transformer
Since Attention is All You Need, transformer has become the foundamental architecture behind the modern LLMs. The original motivation of this paper is trying to solve the issue face by traditional sequential models such as RNNs, LSTMs, particularly in handling long range dependencies efficiently. Ever since then, the development of scalable and efficient LLMs such as GPT has began. Therefore, it is important to learn about the core idea of transformers.
Architecture
High-level
The model component is encoder-decoder with stacked layers of self-attention and FFN . The core idea is about the self-attention mechanism. With the help of the attention, the dependencies between source and target sequences are not restricted by the in-between distance anymore.
Input embedding
d=512. The size of this list is hyperparameter we can set – basically it would be the length of the longest sentence in our training dataset.
Attention Mechanisms
What is Attention?
Attention comes from the inductive bias (assumption) that within or among the sequences, there is a similarity/correlation(syntax relation) between elements. For example, ”The animal didn't cross the street because it was too tired”. What does “it” in this sentence refer to? When the model is processing the word “it”, self-attention allows it to associate “it” with “animal”.
In order to have a better encoding of the word, we can also encode this kind of information into the embedding. In machine learning we often think of “information” as features. Then how to determine which feature vectors are more relevant to a particular feature vector? — Attention! (Information relevance —> Feature relevance)
Similarly in computer vision, attention is, to some extent, motivated by how we pay visual attention to different regions of an image or correlate words in one sentence.
Attention Mechanisms as Information Retrieval Methods
Attention mechanism works very similar as information retrieval methods, where given a query, find relevant keys to retrieve corresponding values using attention score.
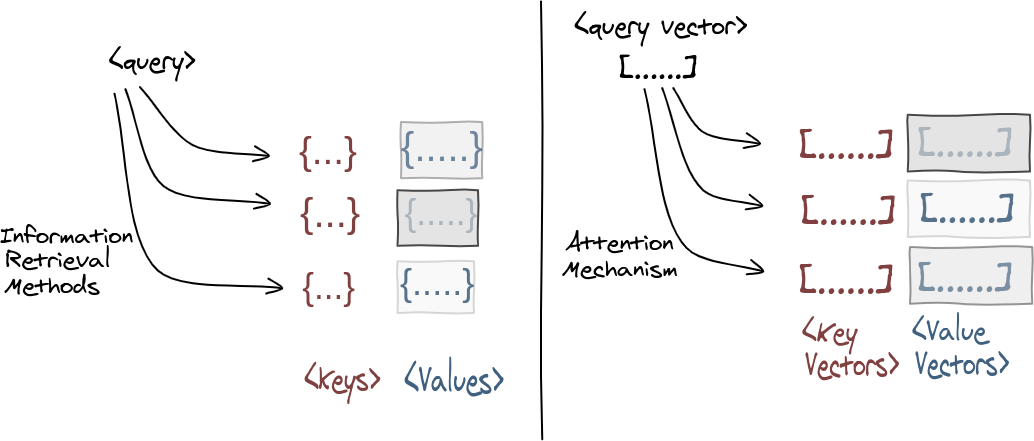
Suppose we have feature vectors , (in natural language, it represents word from a sentence.), then we can obtain the following by projecting the original feature vectors (it can be regarded as choosing what to query like in images, means edge/color…)
- Query: ,
- Keys: ,
- Values: ,
Then we can calculate the relevance between elements of query and key .
- For chosen query, we get its relevance to each key
- To determine the relative importances of key vectors for the query vector, softmax function can be used.
Therefore, the summation of the relevance of each key to the chosen query is equal to 1.
- we can obtain a target vector for query using the weighted sum of all the key-values. Therefore, the attention mechanism describes a weighted average of (sequence) elements with the weights dynamically computed based on an input query and elements’ keys .
Functions to calculate relevance
Two of the most popular approaches to find the relevance are Additive Attention and Dot Product Attention.
- Additive Attention
It uses a single feedforward layer to compute a relevance score.
- Dot Product Attention
Remember that cosine similarity is very common to calculate the relevance between two vectors. And dot product geometrically represents cosine similarity while also taking in account the magnitude of the vectors.
Therefore, the dot product attention between and is:
- Scaled Dot Product Attention
In transformer, a variant of dot product is proposed called scaled dot product attention.
They introduced a scaling factor to prevent softmax from reaching to the regions where gradients are extremely small when the dot product increases.
(the square root of the dimension of the key vectors used in the paper – 64. This leads to having more stable gradients. There could be other possible values here, but this is the default)
This scaling factor is crucial to maintain an appropriate variance of attention values after initialisation. Remember that we initialise our layers with the intention of having equal variance throughout the model, and hence, and might also have a variance close to . However, performing a dot product over two vectors with a variance results in a scalar having -times higher variance:
If we do not scale down the variance back to , the softmax over the logits will already saturate to for one random element and for all others. The gradients through the softmax will be close to zero so that we can’t learn the parameters appropriately.
Self-attention Mechanisms
In attention mechanisms, if the query, and (key, value) pair are from the same sequence, then it is self-attention. Therefore, the encoding using self-attention becomes the contextual representation of the input. On the contrary, if the query and the (key, value) pair are obtained from the different source, then it is cross-attention.
- Self-Attention in Sentences
Here we give the example of self-attention in a sentence.
Calculation of Self-attention in transformer
Here is the illustration of self-attention mechanism in transformer.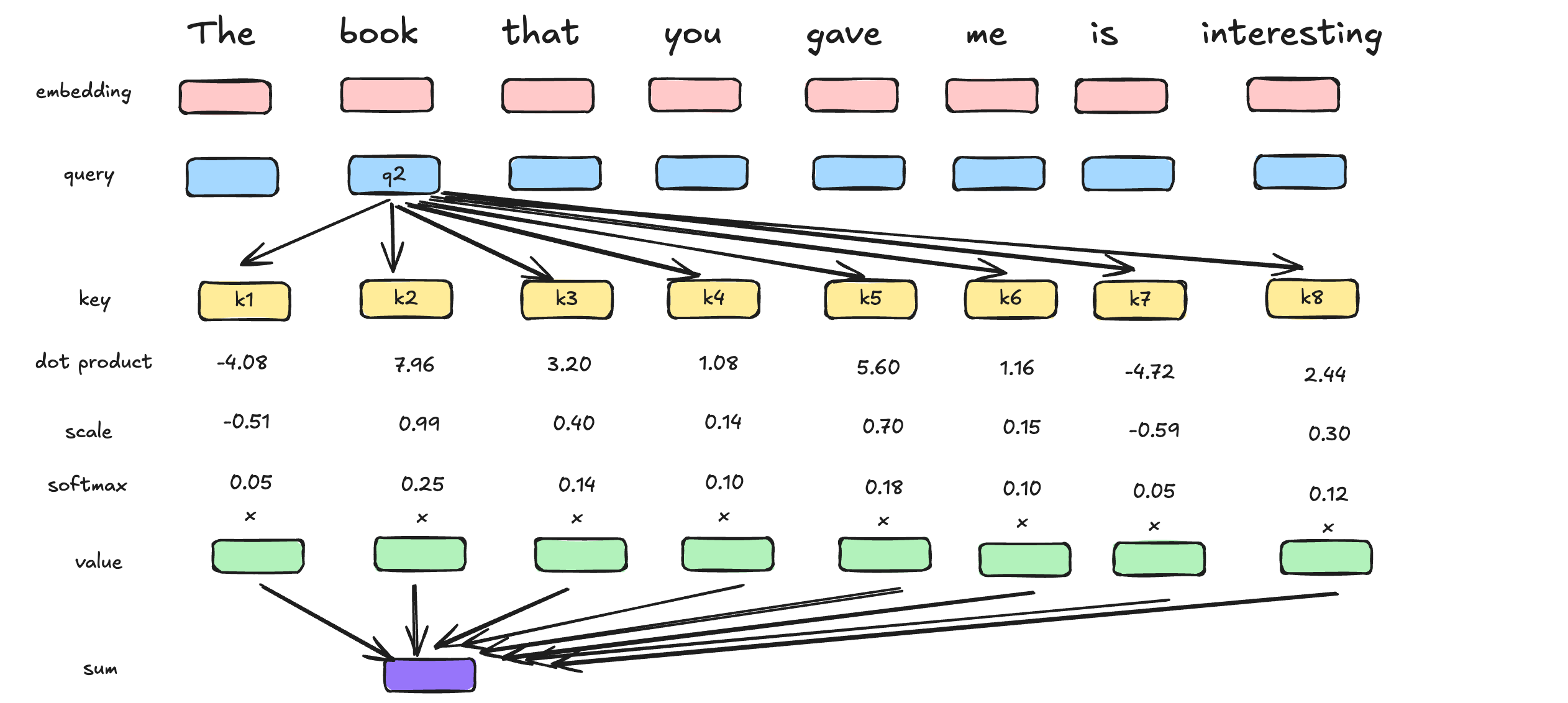
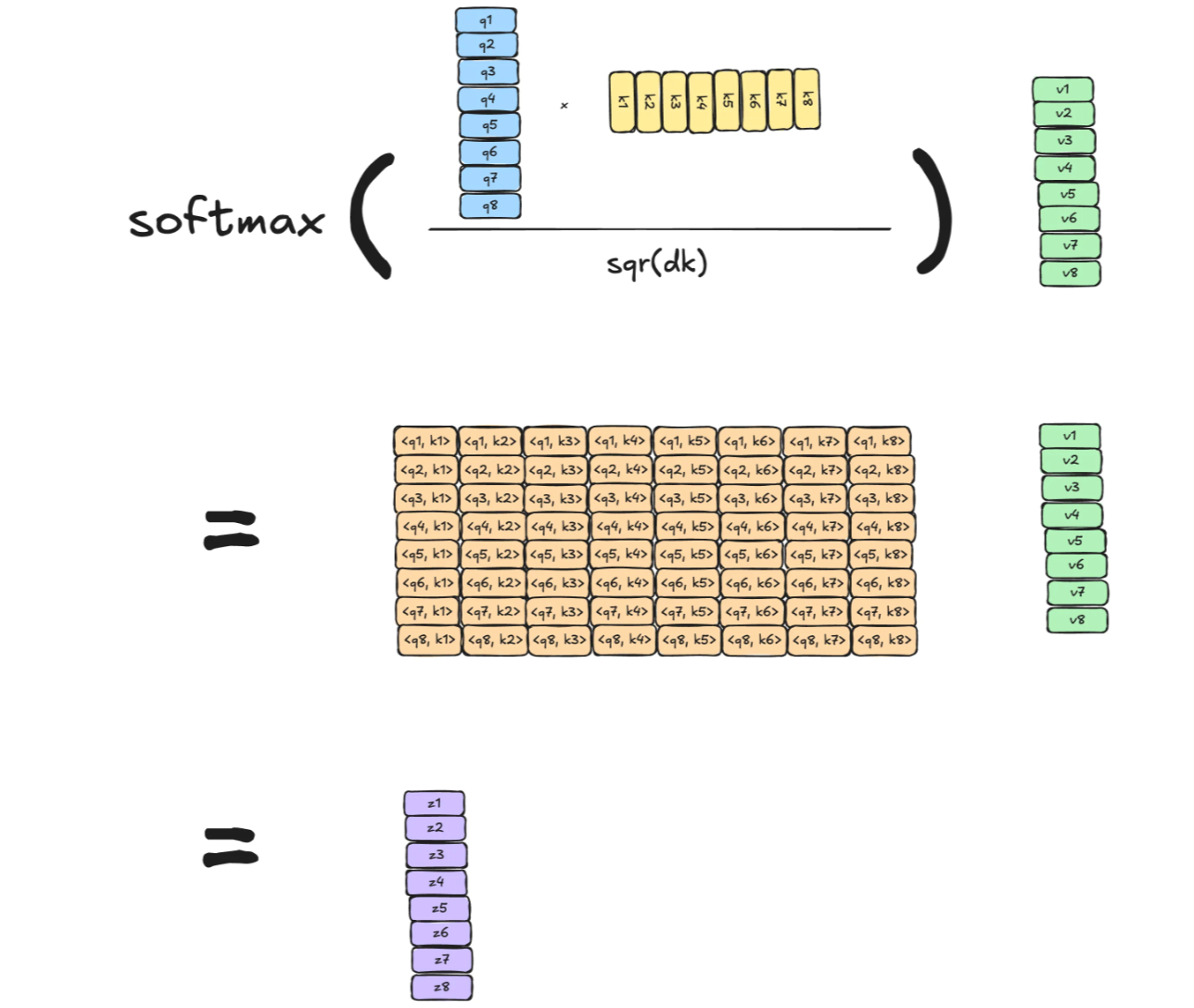
Matrix Calculation of Self-attention in transformer
In the actual implementation, however, this calculation is done in matrix form for faster processing.
- Self-Attention for Image Features
Features captured by a single feature map might make more sense when viewed with features captured by other feature maps. Self-attention helps to find feature representations that are aware of features captured by other feature maps. In this way, attention methods in images help to capture global dependencies in images.
- Self-attention Mechanisms Implementation
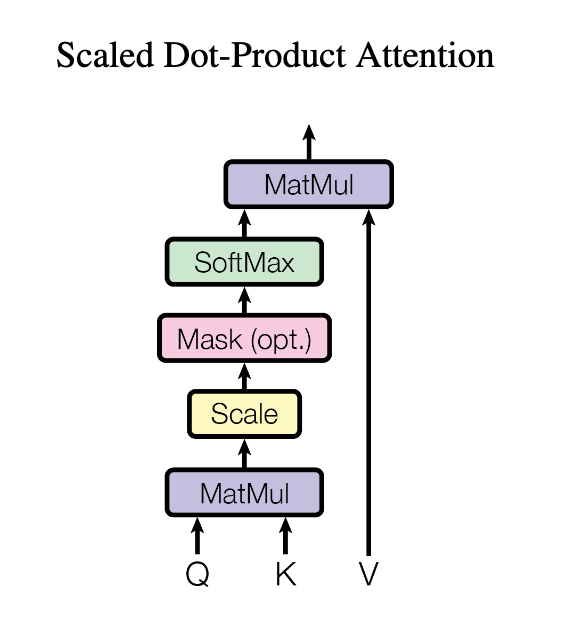
From the implementation figure above, we can find more about the self-attention in transformer - mask: optional masking of specific entries could be applied (or say necessary) in the attention matrix. This is for instance used if we stack multiple sequences with different lengths into a batch. To still benefit from parallelisation in PyTorch, we pad the sentences to the same length and mask out the padding tokens during the calculation of the attention values. This is usually done by setting the respective attention logits to a very low value.
attn_logits = attn_logits.masked_fill(mask == 0, -9e15),在mask==0的地方用-9e15填充,比设定length短的地方设置为0,在计算attention的时候也会softmax近似为0, and in deocing, you don;t wanna expect to see the future output.
why self-attention works better?
how the contextual representation is better than just a transformation using fully connected layers. The word bat bat can have several meanings for example the bird or as the verb to refer to the action of batting. The context however constrains the meaning to a cricket bat.
shared across feature maps
Multi-Head Attention Mechanism
What is Multi-Head Attention
Let’s learn from how to implement it first.
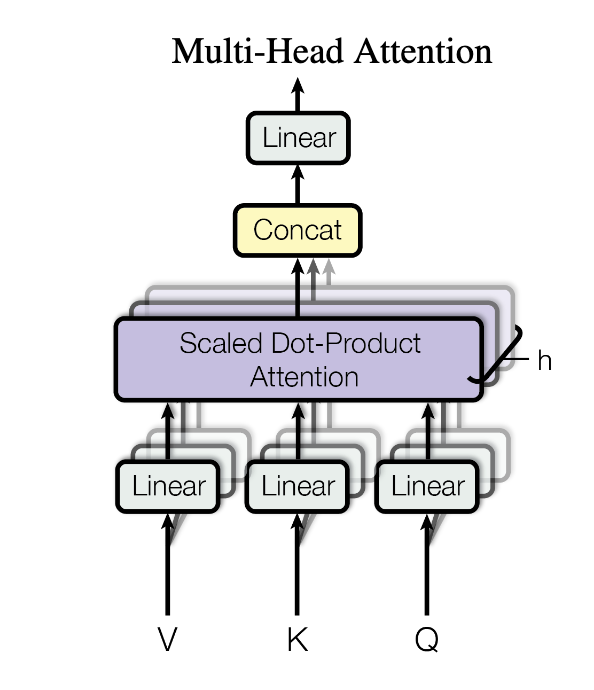
Consider a 4-head attention method. In this case, each of the query, key and value vectors (say dim=512) is divided into 4 heads (now each have dim=512/4=128). Self-attention is then be used to find the contextual representations of each of the four heads across the input vectors. The output will be concat together (back to dim=4*128=512), and once again project by a linear layer. Why add linear layer after concat
Why using Multi-Head Attention
From the implementation above, we know that multi-attention is more like a parallel version of partitioned single-head attention. Even though single-head attention is able to attend to the correlation between elements, yet often there are multiple different aspects a sequence element wants to attend to, and a single weighted average is not a good option for it. This is why we extend the attention mechanisms to multiple heads.
Therefore, multi-head attention allows the model to jointly attend to information from different representation subspaces at different positions.
- different positions: It expands the model’s ability to focus on different positions. For instance, the word may have a strong correlation with the next word, but it can also be strongly correlated with the word before when viewed from a different perspective.
- different subspaces: It gives the attention layer multiple “representation subspaces” multiple sets of Query/Key/Value weight matrices. For example, if we want to pay attention to both subjective and adverts, single-head attention can not attend to both because all information have been averaged and model cannot effectively distinguish between different type of feature. In multi-head attention, each head could attend to different aspect of feature. The concatenation make it a richer representation.
Position-wise Feed-Forward Networks
As discussed above, the main part of the self-attention mechanism is linear (e.g. linear projection). In order to increase the non-linearity of the model, feed-forward networks is involved. In this way, model can represent more complex patterns, and also capture more fine-grained features.
Another points is “position-wise”, which means feed-forward networks is applied to each position separately and identically without considering context. The output from self-attention has already encode the dependencies among each element. Then these embeddings each independently are input into the FFDN, there is no dependencies involved, thus can be executed in parallel.
This MLP adds extra complexity to the model and allows transformations on each sequence element separately. You can imagine as this allows the model to “post-process” the new information added by the previous Multi-Head Attention, and prepare it for the next attention block. Usually, the inner dimensionality of the MLP is 2-8 larger than , i.e. the dimensionality of the original input . The general advantage of a wider layer instead of a narrow, multi-layer MLP is the faster, parallelizable execution. In practical, it will first project the embedding into higher dimension 2048, then project back to the original dimension 512.
Positional Encoding
Either in (multi-head) self-attention or position-wise feed-forward networks, the order of the input/embedding will not affect the output — permutation-equivariant. More specifically, if we switch two input elements in the sequence, the output is exactly the same besides the elements 1 and 2 switched. This means that the multi-head attention is actually looking at the input not as a sequence, but as a set of elements.
In tasks like language understanding, however, the position is important for interpreting the input words. In order for the model to make use of the order of the sequence, we must inject some information about the relative or absolute position of the tokens in the sequence. The position information can therefore be added via the input features.
We could learn a embedding for every possible position, but this would not generalize to a dynamical input sequence length. Hence, the better option is to use feature patterns that the network can identify from the features and potentially generalize to larger sequences.
Residual connection
Similar to ResNets, Transformers are designed to be very deep. Some models contain more than 24 blocks in the encoder. Hence, the residual connections are crucial for enabling a smooth gradient flow through the model.
“Without the residual connection, the information about the original sequence is lost. Remember that the Multi-Head Attention layer ignores the position of elements in a sequence, and can only learn it based on the input features. Removing the residual connections would mean that this information is lost after the first attention layer (after initialisation), and with a randomly initialised query and key vector, the output vectors for position has no relation to its original input. All outputs of the attention are likely to represent similar/same information, and there is no chance for the model to distinguish which information came from which input element. An alternative option to residual connection would be to fix at least one head to focus on its original input, but this is very inefficient and does not have the benefit of the improved gradient flow.”
Layer Normalization
- it enables faster training and provides small regularization
- ensures that the features are in a similar magnitude among the elements in the sequence
- why not using batch normalization: because it depends on the batch size which is often small with Transformers (they require a lot of GPU memory), and BatchNorm has shown to perform particularly bad in language as the features of words tend to have a much higher variance (there are many, very rare words which need to be considered for a good distribution estimate).
Liminations
- Interpretability:it does not necessarily reflect the true interpretation of the model (there is a series of papers about this, including Attention is not Explanation and Attention is not not Explanation).
- Attention mechanism improvement
- sparse attention
- linear attention
GPT: The first Transformer-based pretrained model for NLP
- Unidirectional
- Uses the Transformer decoder, focusing only on generation (though in retrospect, it also plays a role in understanding).
Meanwhile pretrained models
Bert: masking
- Bidirectional? Why unidirectional better than bidirectional?
- point out: bigger is better
- transformer encoder cuz address understanding
T5
- keep scaling
- integrate all NLP task into one language model (e.g. classification, answer generation)
- encoder for text understanding, decoder for unidirectional generation
- both input and output are tokens,
Langue modeling is an extreme form of multi-task learning: reasoning, coding…
compression?
corpora
perplexity
GPT-2
- keep scaling, unidirectional, can solve multiple tasks
GPT-3
- Cross-task generalization, in context learning, higher bound for “imagination”
- InstructGPT & ChatGPT
GPT-4
Unlike previous GPTs, GPT-4 is a multimodal model, meaning it can process both text and image inputs while generating text-based outputs. Built on a Transformer-style architecture, GPT-4 was pre-trained using vast amounts of publicly available and third-party licensed data, with the goal of predicting the next token in a given context. Following pre-training, it was further fine-tuned using Reinforcement Learning from Human Feedback (RLHF) to enhance its alignment with human intention and safety considerations.
In their technical report, it doesn’t contain any further details about the architecture, hardware, training compute, dataset construction, training method, or similar. The four main parts covered are:
- Predictable Scaling: trying to make performance predictions based on models trained with less compute. Predictable scaling, refers to predict performance as the model scales in size with less compute. GPT-4 is a very large scale model, therefore it is very hard to do extensive model-specific tuning. To address this problem, OpenAI developed infrastructure and optimization methods that have very predictable behavior across multiple scales. By doing so, before training, you’ll have idea about the model expected performance, which is useful for safety control and decisions around alignment, safety, and deployment.
- Capabilities: GPT-4 demonstrates human-level performance on various professional and academic benchmarks, ML benchmarks, Visual input benchmarks, making significant advancements in reasoning, comprehension, and problem-solving.
- Limitations: it still has limitations as previous GPT series (even with mitigations), such as hallucinations, biases, and computational constraints.
- Safety improvements: Adversarial Testing via Domain Experts, Model-Assisted Safety Pipeline with an additional set of safety-relevant RLHF training prompts and a rule-based reward models (RBRMs).
References
https://jalammar.github.io/illustrated-transformer/
https://jalammar.github.io/illustrated-gpt2/
https://nlp.seas.harvard.edu/2018/04/03/attention.html
https://www.youtube.com/watch?v=P127jhj-8-Y&list=PLoROMvodv4rNiJRchCzutFw5ItR_Z27CM
https://www.youtube.com/watch?v=XfpMkf4rD6E
https://zhuanlan.zhihu.com/p/2344632495
https://zhuanlan.zhihu.com/p/632825694
https://zhuanlan.zhihu.com/p/679715351
https://zhuanlan.zhihu.com/p/639252603